午前
データ解析
午後
データ解析
卒論手伝い(文章添削)
修論論文化に向けたデータ解析の目処がたった。
5年間の標識再捕法という素晴らしいデータをどうにか公開しなければという強い思いで取り組んでいるが、知識不足で文献を読むたびに新しいアイデアが出て修正を繰り返す日々が続いていた。
当初は、開放系個体群なので使い慣れたJolly-Seberであっさり終わるハズだった。
しかし、関連しそうな文献を読んでいると「POPAN」の5文字を良く目にした。
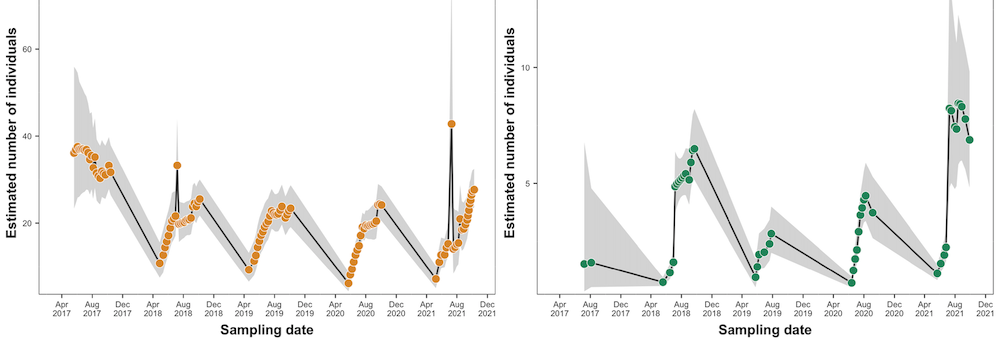
POPANは標識再捕法による個体数推定法の一つで、各調査機会(or調査機会の間)における個体群の生存確率(φ)、捕獲確率(p)、加入確率(pent)のパラメーターを算出しつつ、スーパー個体群というものを推定する(ただし、基本的な考え方はJorry-Seberと同じ!)。
スーパー個体群は、調査期間中(修論だと5年間)に一度でも存在していた全個体数を含む想像上の個体群のこと。この「全個体数」は実際に標識をつけた個体だけでなく推定個体も含まれる。
最初、このスーパー個体群に生態学的な意味を見出そうとして苦労した。これ自体は生物学的にはあまり意味はないけど(?)、スーパー個体群を推定することで、各パラーメーター推定が安定することに大きな意味がある。
ちなみに、各調査機会(or調査機会の間)の生存確率(φ)、捕獲確率(p)、加入確率(pent)のパラメーターが推定できると、各調査機会の個体数推定ができる。
つまり、スーパー個体群を推定することで、ある時点の個体数の推定精度が上がる、、、というのが私の理解。
Jolly-Seberでもできるらしいが、POPANではパラーメーター推定の際に環境データを共変量として組み込むことができる。
例えば、「気温が生存確率に影響するモデル」、「気温が生存確率に、降水量が捕獲確率に影響を及ぼすモデル」を構築して、それぞれのAICを算出して、より説明能力の高いモデルを選定することができる。私にはこれが魅力的だった!
解析にはMARKプログラムが使われることが多く(ほぼ一択?)、RMarkパッケージを使うことでRからMARKを実行することもできる。webサイトもあるみたい。
上図は推定結果。ナカナカ良い感じ。