
午前
データ解析
個人ゼミ
午後
生態学ゼミ
面談
データ解析
卒論論文化のデータ解析でハマってしまった。本日は解決できずに断念。
完全に停滞したので、卒論の解析用資料を作成しようとしたのだが、楽しくなって暴走してしまった。
音を定量化した音響指数というのがある。
例えば、音圧の変異を算出したAcoustic Complexity index(ACI)は鳥類の多様性と関係があるという報告がある。
そして、このような音響指数を用いて自然を評価できないか、また、生物に悪影響を及ぼす音景観を見つけよう、ということが研究されている。今年の卒論では、これを少し使ってみよう、、、で、その参考資料を作ろうと思ったのだが、、、。
指数の算出は簡単でwavファイルとして録音した音声ファイルを、例えば、Rのsoundecologyパッケージで解析すれば良い。
最初は、真面目に学生が録音した音声データを使って試したのだが、データが重いのか、一斉解析が終わらない、、、。設定が悪いのか、ファイルが大きいせいか分からないので、もう少し軽いデータを試したい、、、と考えたのが暴走の始まりだった。
軽い音声データ、、、スマホの音楽データを使ってみるか、と。
ひとまず、mp3ファイルを任意のディレクトリに入れる。その後はRに頑張ってもらう。
#ライブラリの読み込み
library(soundecology)
library(tuneR)
library(bioacoustics)
library(tidyverse)mp3をwavに変換。
#1ファイルずつ実行する場合
mp3_to_wav("mp3のPATH". "wavを出力したいディレクトリのPATH")
#ディクレトリのファイル全てをloopで実行する場合
path_list <- paste("ディレクトリのPATH", list.files("ディレクトリのPATH"), sep="/") #setwd()がうまくいかないので絶対PATHを作成
#loop
for (i in 1:length(name_list)) {
mp3_to_wav(path_list[i], "wavを出力したいディレクトリのPATH")
}下記のコマンドでディレクトリ内の全てのwavファイルを対象にNormalized Difference Soundscape Index(NDSI)を計算できる。
multiple_sounds(directory = "ディレクトリのPATH", resultfile = "ndsi_results.csv", soundindex = "ndsi", no_cores = "max")
#1ファイルだけ解析する場合
ndsi(wavのPATH)soundindex=""を「acoustic_complexity」、「acoustic_diversity」、「acoustic_evenness」、「bioacoustic_index」に変更することで、それぞれの指数を計算できる。
算出したデータを「data」オブジェクトに入れたとする。

データndsiの順に並び変える。
#ndsiの順に並べ替える
ndsi_sort <- data %>%
arrange(ndsi)
#上記の順番をFILENAMEに当てはめる;X軸に順番に反映される
ndsi_sort$FILENAME <- factor(ndsi_sort$FILENAME, levels=ndsi_sort$FILENAME)各楽曲のNormalized Difference Soundscape Index(NDSI)は以下の通りでした!
ggplot(data=ndsi_sort, aes(x=FILENAME, y=ndsi)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1, size = 15),
text = element_text(family="HiraKakuPro-W3"))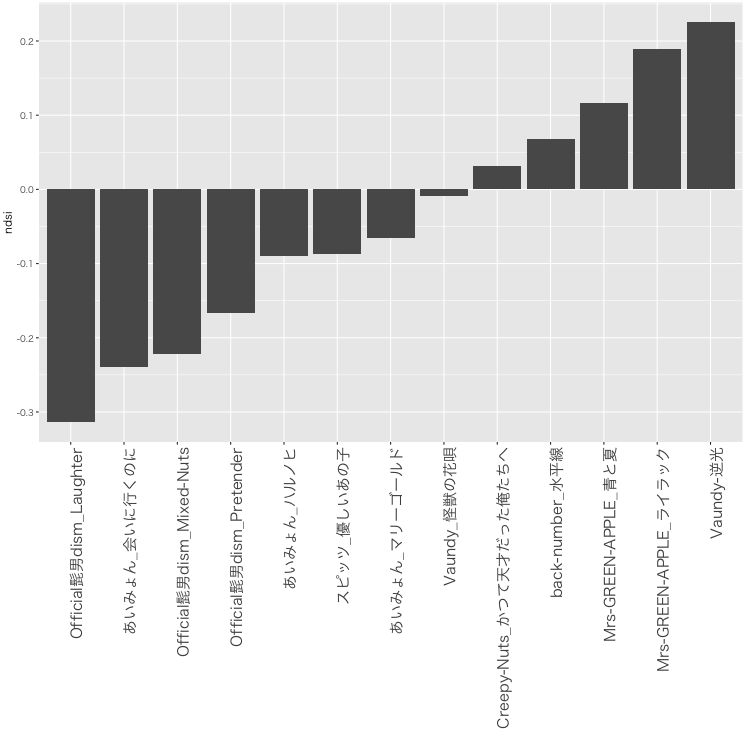
結構、綺麗に髭男とあいみょんが低く、VaundyとMrs. Green Appleが高い傾向がみられた。
ちなみに、NDSIは「2–12 kHz」と「1–2 kHz」の割合で、音響景観の世界では、前者は生物音、後者は人工物音として扱われている。Vaundyの逆光が高いのは納得か?髭男は結構低音が多い?
各楽曲のNDSI、Acoustic Diversity、Acoustic Evenness、Bioacoustic Indexを使ってPCAもやってみた。
#FILENAME列を行名にする
DATA <- column_to_rownames(data, "FILENAME")
#NaNを含む「acoustic_complexity」列を削除
DATA_select <- DATA %>%
select(-acoustic_complexity)
#行と列を入れ替え
DATA_complete <- t(DATA_select)
#PCAの実行
PCA <- prcomp(DATA_complete)
#主成分得点をデータフレームとして取り出す
PCA_score <- data.frame(PCA$rotation)
#凡例用に歌手名を追加
PCA_score$artist <- c("Back Number", "Creepy Nuts", rep("Mrs. Green Apple",2), rep("Official髭男dism", 3), rep("Vaundy", 2), rep("あいみょん", 3), "スピッツ")
#作図
ggplot(data=PCA_score, aes(x=PC1, y=PC2, color=artist, alpha=0.5)) +
geom_point(size=15) +
theme(text = element_text(size=15, family="HiraKakuPro-W3"))結果はこんな感じ。
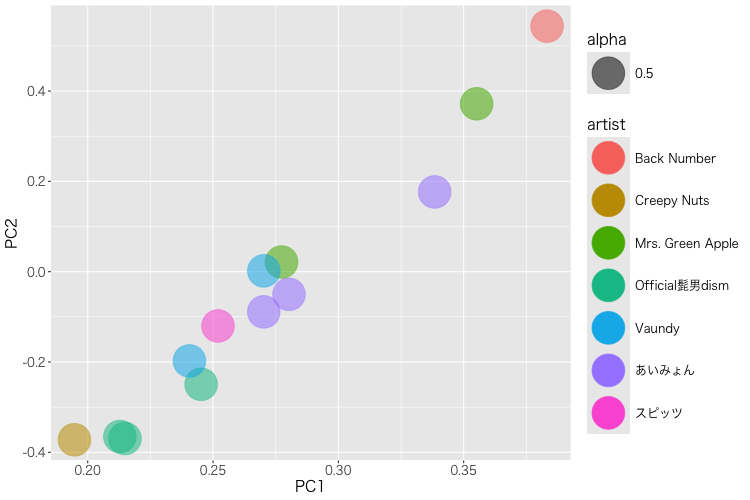
髭男は左下でまとまっている、、、。私はこんな感じの曲を好きなのか?
この中だとback numberの「水平線」、Mrs. Green Appleの「青と夏」、あいみょんの「会いに行くのに」が他とは結構違う結果だけど、、、どうかね。
音楽を解析するための指数ではないので、この解析には意味がない。でも、データ解析って面白い、と思ってくれたら嬉しい。
学生は基本、解析がキライなんだよね。少し勉強すれば、これぐらいはすぐにできるようになるのだけど。