
目次
午前
卒論手伝い(データ解析)
授業
午後
授業準備
卒論手伝い(データ解析)
論文書き
卒論の手伝いで多重比較の結果(処理間の差をアルファベットで描く)を描く方法を勉強した。
そもそも、多重比較の手法そのものに悩んでいるが、ひとまず、今回は、glmでモデル選択をしたのち、emmeans( )を使って推定周囲平均(Estimated Marginal Means)を用いて比較した。
#ライブラリ
library(tidyverse)
library(emmeans)
library(multcomp)
#仮想データの作成
##5地点で気温を計測し、反復は10とする。
set.seed(123) # 再現性のため
temp <- c(runif(10, min = 5, max = 10), runif(10, min = 20, max = 25), runif(10, min = 20, max = 30), runif(10, min = 35, max = 55), runif(10, min = 5, max = 40)) #気温データ:各地点ごとにminとmaxを変更して10の乱数を発生
site <- rep(LETTERS[1:5], each=10) #地点データ:LETTERS[1:5]はアルファベットA~Eの意味
DF <- data.frame(temp, site)
#地点ごとの推定平均
(emm <- emmeans(model, ~site, type="response"))
#site response SE df lower.CL upper.CL
#A 7.89 0.579 45 6.81 9.15
#B 22.62 1.660 45 19.51 26.22
#C 26.16 1.920 45 22.56 30.32
#D 45.76 3.360 45 39.47 53.05
#E 17.09 1.250 45 14.74 19.81
#多重比較の実行
pairs(emm, adjust="tukey")
#contrast ratio SE df null t.ratio p.value
#A / B 0.349 0.0362 45 1 -10.143 <0.0001
#A / C 0.302 0.0313 45 1 -11.544 <0.0001
#A / D 0.172 0.0179 45 1 -16.932 <0.0001
#A / E 0.462 0.0479 45 1 -7.443 <0.0001
#B / C 0.865 0.0898 45 1 -1.400 0.6305
#B / D 0.494 0.0513 45 1 -6.788 <0.0001
#B / E 1.323 0.1370 45 1 2.700 0.0697
#C / D 0.572 0.0593 45 1 -5.388 <0.0001
#C / E 1.531 0.1590 45 1 4.100 0.0015
#D / E 2.678 0.2780 45 1 9.488 <0.0001
#p.valueが<0.05の組み合わせに異なるアルファベットを記したい!
#有意差のある組み合わせをアルファベットで記述してくれる!
(cld <- multcomp::cld(emm, adjust="tukey", Letters=letters))
#site response SE df lower.CL upper.CL .group
#A 7.89 0.579 45 6.48 9.61 a
#E 17.09 1.250 45 14.04 20.81 b
#B 22.62 1.660 45 18.58 27.54 bc
#C 26.16 1.920 45 21.48 31.85 c
#D 45.76 3.360 45 37.58 55.71 d
#上記の結果にデータの最大*1.05列を準備して、ggplotでY軸の値として使う!
cld_df <- as.data.frame(cld) %>%
mutate(y = max(DF$temp) * 1.05)
#作図
ggplot(data=DF, aes(x=site, y=temp)) +
geom_boxplot() +
geom_point() +
geom_text(data=cld_df, aes(x=site, y=y, label=.group), col="red", size=10)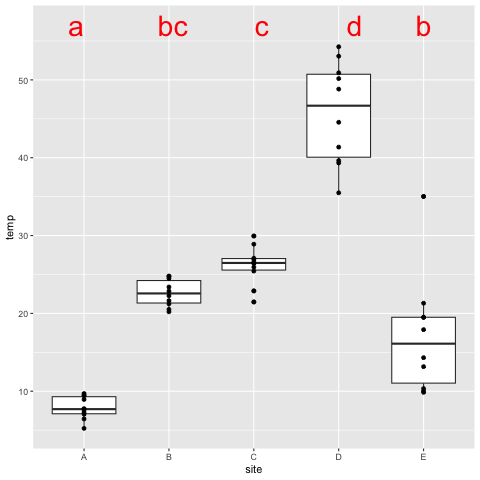
上記は全データの最高値の1.05倍の地点にアルファベットを配置している。
例えば、アルファベットを「各」データの最高値の上に表示したいこともある。
#上記が実行されているとする
#cldをデータフレームにする
cld_df <- as.data.frame(cld)
#各地点のmaxを計算し5を足した列を作成
##任意の数値を掛けると最大値によってデータからアルファベットの距離が異なる!
DF_max <- DF %>%
group_by(site) %>%
summarise(MAX=max(temp)+5)
#データの結合
DF_com <- left_join(cld_df, DF_max, by="site")
##作図
ggplot(data=DF, aes(x=site, y=temp)) +
geom_boxplot() +
geom_point() +
geom_text(data=DF_com, aes(x=site, y=MAX, label=.group), col="red", size=10)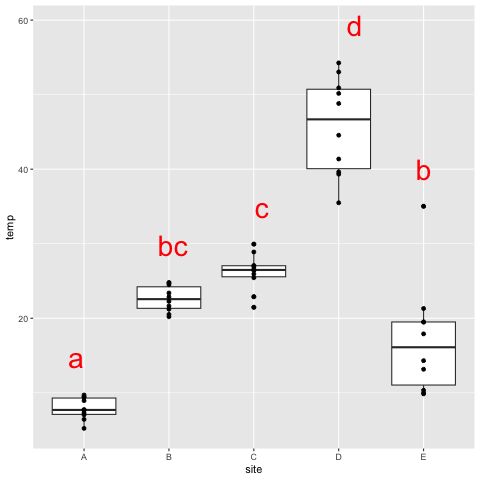
「max(temp)+5」で最高値+5の位置に描くことにしているが、ここを第3四分位にすれば箱の上に描けるはず。