
午前
ハンミョウ調査
午後
資料作成
8月締切書類、最後の1報にやっと着手。あと数日の戦い。
野外調査を論文化する際には、しばしば、気温や降水量のデータが必要となる。
有難いことに気象庁のHPからダウンロードすることができる。
グラフにしたいときは、ダウンロードしたCSVをRに取り込むことになるのだが、この一手間が面倒くさい。
と思っていたら、やはりありました。Rから気象庁データを取得するパッケージ「jmastats」。
中心となる関数は「jma_collect( )」で、下記が基本となるコマンド。
jma_collect(item=" ", block_no=" ", year=, month=, cahce=FALSE)「item」はデータの期間を記入する項目で、「annually」だと年ごと、「monthly」だと月ごと、「daily」だと日ごとのデータが取得できる。他にも色々ある。
「block_no」はデータを取得したい観測所のIDを書く。
当然、そんなIDは知らないので調べる必要がある。緯度経度を入力することで最寄りの観測所を調べることもできるようだが、うまくできなかった。私の理解不足が問題だと思う。
強引なやり方だけど、下記の方法で探せる。
data("stations", package = "jmastats") #気象データ(stations)の読み込み
stations #全気象観測所を出力
#鳥取の観測所のみを出力する場合
stations %>%
filter(area=="鳥取")鳥取大学最寄りの湖山観測所のblock_noは1519であった。
2015年6月の湖山観測所の日ごとのデータを取得するには、下記とすれば良い。
jma_collect(item="daily", block_no="1519", year=2015, month=6, cache = FALSE)しかし、ここから結構、苦戦した。
上記を実行すると、下図のようにセルに「<tibble>」と書かれる。
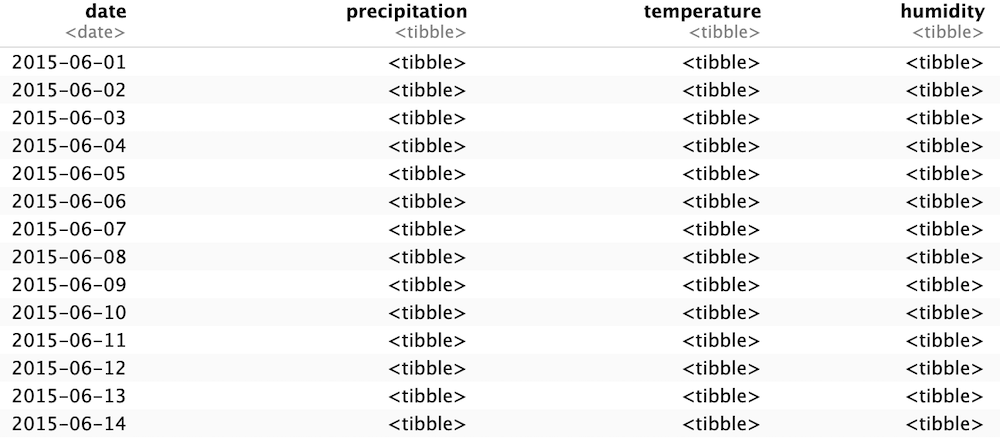
この意味が良く分からず、上記のコマンドを色々とイジって時間を費やした。
ChatGPTに相談したら「セルの中にリスト化されてデータが入っているからだよ」と教えてくれた。
そして、「アンネストすれば良い」と教えてくれて、ついでにコマンドも。
jma_collect(item="daily", block_no="1519", year=2015, month=6, cache = FALSE) %>%
unnest()今回は、2015年から2024年の6月から9月のデータが欲しい。個別で指定して結合すれば良いのは分かるけど、ループでどうにか処理をしたい。
これもChatGPTに丸投げしたら、一発で正解を教えてくれた。
# 取得したい年と月
years <- 2015:2024
months <- 6:9
# 年×月の組み合わせを作成
grid <- expand_grid(year = years, month = months)
# jma_collect() を各組み合わせに実行
res_all <- grid %>%
mutate(data = pmap(list(year, month), function(y, m) {
jma_collect(item = "daily", block_no = "1519", year = y, month = m, cache = FALSE)
}))「res_all」のデータを見るには、「unnest( )」を2回実行する必要がある(正しいのか不明)。
res_all %>%
unnest() %>%
unnest()